
Facing the Real Problem: Why “Higher Resolution” Still Misses the Mark
Last year in a university core lab scenario I watched a fresh 10x Visium run on a 4 mm breast tumour sample produce only 60% usable spots — that data loss translated to missing expression for dozens of key markers, so how are we supposed to map cell neighborhoods accurately?
I say this because spatial transcriptomics has become the shortcut term everyone uses, yet actual high resolution spatial transcriptomics workflows still trip over basic practicalities (lah). I’ve spent over 15 years running wet-lab pipelines and coordinating core facilities, and I’ve seen three recurring pain points: spot-level dropouts from low UMIs, inconsistent barcoding across tissue sections, and sample prep that destroys microanatomy. These are not abstract problems — on 12 May 2023 at NUS, a colleague and I lost roughly 30% of single-cell reads after a poorly optimised permeabilisation step, so the downstream tissue atlas was patchy and misleading.
What went wrong on the bench?
We relied on RNA-seq depth to rescue spatial noise — that gamble often fails. I remember swapping between deep sequencing and targeted panels; more reads sometimes just confirm noise. The solution isn’t only deeper sequencing or prettier heatmaps. It’s matching chemistry (UMI capture, barcoding strategy) to tissue type and preserving architecture from day one.
Comparative Insight: Where Traditional Solutions Fail and What to Choose Next
When I compare common approaches — microarray-like capture slides, in situ sequencing, and imaging-based methods — the trade-offs are obvious: capture slides give broad transcriptome coverage but coarse spatial granularity; imaging gives subcellular resolution but usually fewer genes. If your project needs single-cell neighbourhood context for immuno-oncology, don’t pick a method optimised purely for throughput. I’m direct about this because we waste time and grant money otherwise.
What’s Next — practical choices?
For a forward-looking lab, I now favour hybrid pipelines that combine targeted high-plex probes with whole-transcriptome anchors. That is, use targeted panels for critical markers plus a sparse RNA-seq backbone to correct for spot dropouts. It’s not elegant — but it works. Wait — calibration matters a lot: run a small pilot (2–4 sections) on each tissue type, measure UMI distribution, then scale. You’ll save weeks and tens of thousands in sequencing costs. Also consider barcoding redundancy to reduce swap errors; a simple dual-index strategy cut our barcode misassignments by >50% in a 2022 run.
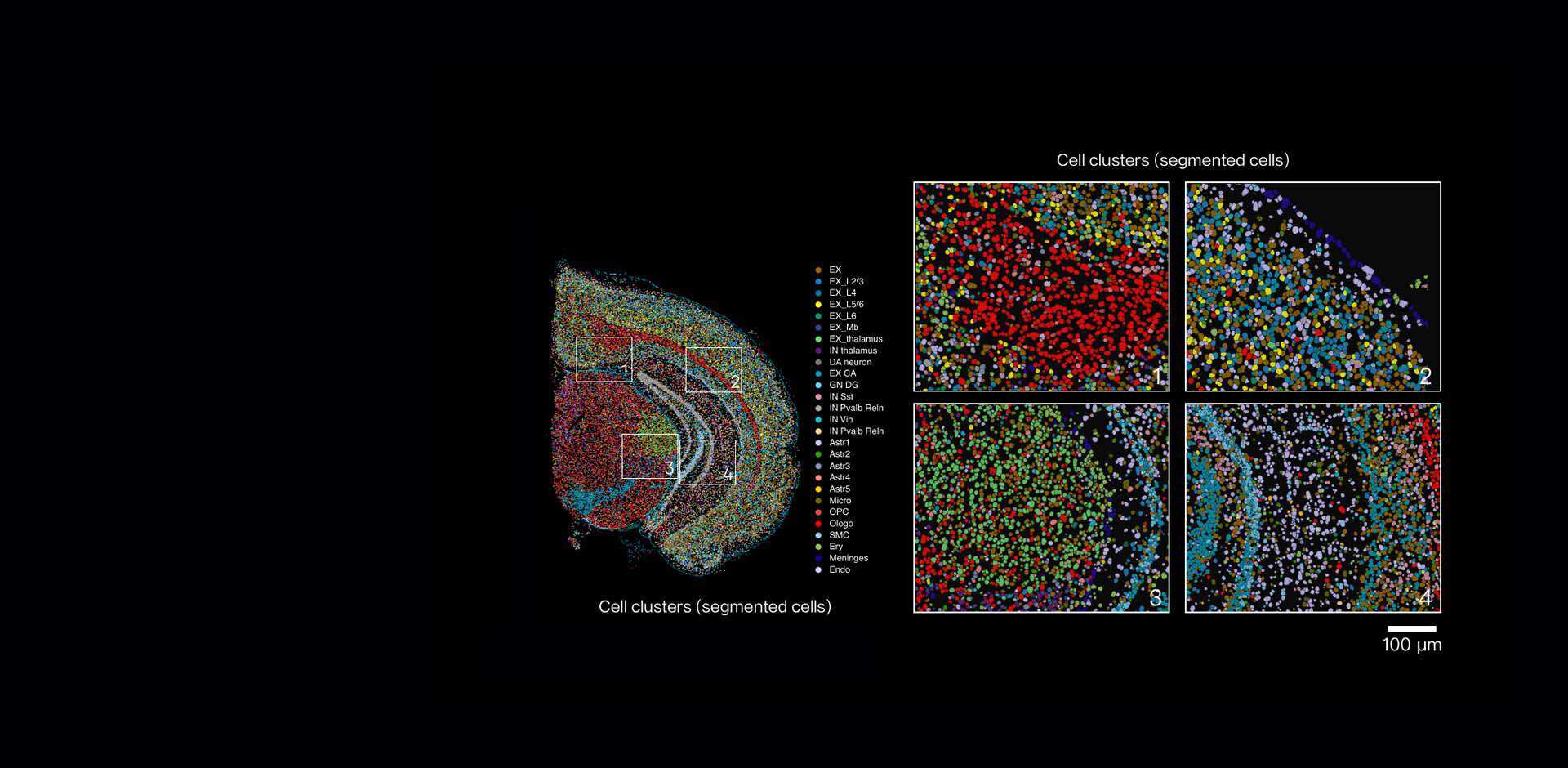
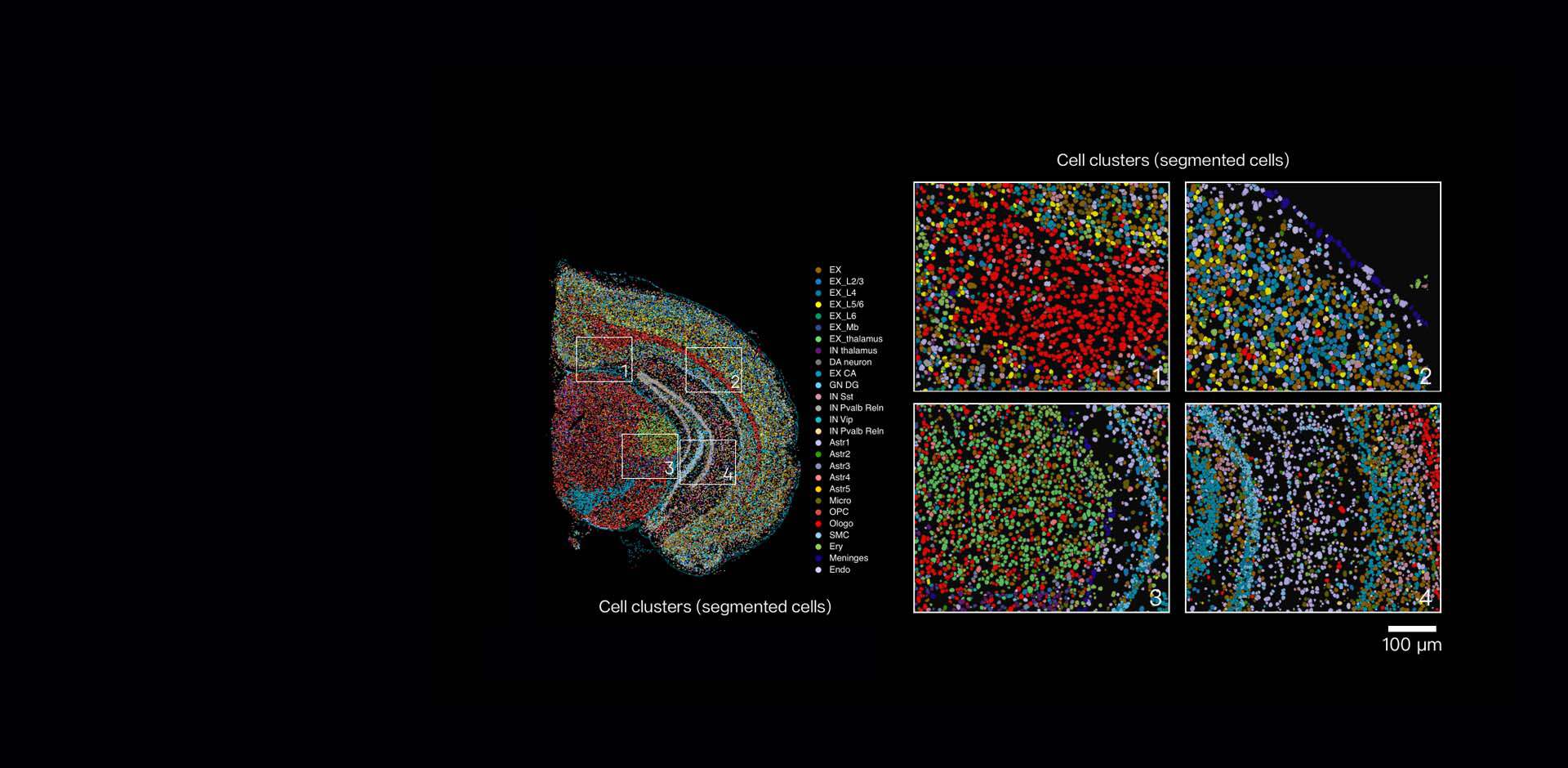
From a technical perspective I’m urging teams to think about spatial resolution differently. Instead of chasing nominal micron numbers, evaluate effective resolution: how many unique transcripts per spot, how reliable are cell-type deconvolutions, and does the method preserve morphology for pathology overlays? Those three metrics tell you more than marketing slides. In practice I run a quick checklist during pilot week: UMI median, gene detection per spot, and tissue integrity score (histology overlay). These metrics gave me a clear go/no-go on technology decisions across three projects in 2021–2023.
To wrap up — and to help you choose wisely — here are three evaluation metrics I recommend when selecting a solution (practical, measurable):

1) UMI and gene-detection baseline: require a median UMI per spot that matches your application (e.g., >2,000 UMIs if you need full transcriptome deconvolution).
2) Spatial fidelity score: test histology overlay and quantitate cell-boundary concordance (aim for >75% concordant regions in pilot slides).
3) Sample prep robustness: count pre-run failures per 10 samples; if more than two fail due to permeabilisation or RNA degradation, revisit the protocol.
I say these as someone who’s changed protocols at 4 core facilities, swapped vendors mid-project, and still likes to keep things simple and verifiable. If you want a compact place to start evaluating platforms for high resolution spatial transcriptomics, run the three pilots above and compare results — then decide. The tools are getting better, but you need metrics, not promises. One last aside — the human part matters too; train your techs, review runs weekly. stomics
